Abstract
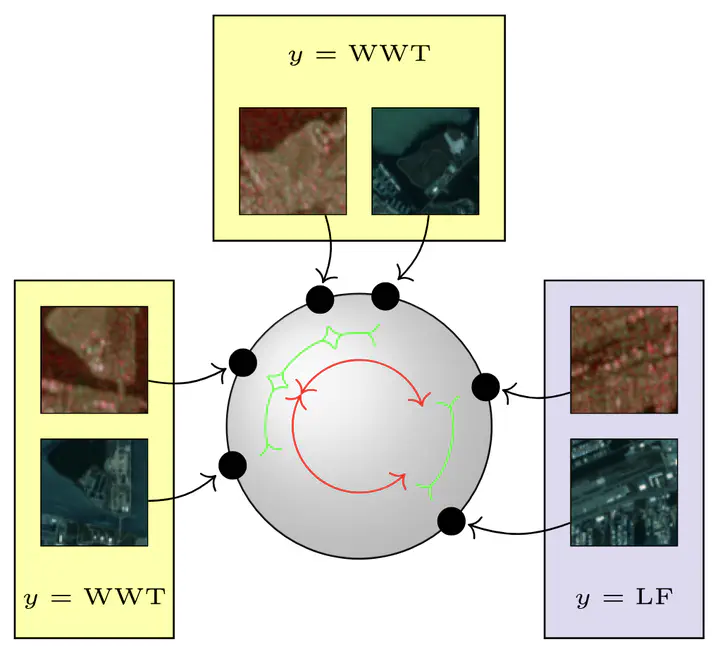
To leverage the large amount of unlabeled data available in remote sensing datasets, self-supervised learning (SSL) methods have recently emerged as an ubiquitous tool to pretrain robust image encoder models from unlabeled images. However, when used in a downstream setting, these models often need to be fine-tuned for a specific task after their pretraining. This fine-tuning still requires labeling information to train a classifier on top of the encoder while also updating the encoder weights. In this letter, we investigate the specific task of multimodal scene classification where a sample is composed of multiple views from multiple heterogeneous satellite sensors. We propose a method to improve the categorical cross-entropy fine-tuning process which is often used to specify the model for this downstream task. Our approach, based on the supervised contrastive (SupCon) learning, uses the label information available to train an image encoder in a contrastive manner from multiple modalities while also training the task-specific classifier online. Such a multimodal SupCon loss helps better align representations from samples coming from multiple sensors but having the same class labels, thus improving the performance of the fine-tuning process. Our experiments on two public datasets including DFC2020 and Meter-ML with Sentinel-1/Sentinel-2 images show a significant gain over the baseline multimodal cross-entropy loss.
Add the full text or supplementary notes for the publication here using Markdown formatting.